Lecture sLM, sLLM
Table of contents
LLM은 수천억에서 수조개의 parameter를 가지고 있기 때문에, 이를 학습하기 위해선 많은 resource가 필요하다. 따라서, 빠른 모델 훈련과 배포를 위해 sLM(small Language Model), sLLM(smaller Large Language Model)의 필요성이 대두된다.
sLLM은 일반적으로 10B 이하의 parameter를 가지고, sLM은 1B 이하의 parameter를 가진다.
LM Model 평가 방법
LLM에서 평가는
- LLM 모델 자체에 대한 평가
- 기본 LLM에 대한 전반적인 성능 평가
- GT와 비교하여 점수를 매기는 리더보드 활용
- ex) HellaSwag, TruthfulQA, MMLU, ARC, …
- LLM 기반 시스템에 대한 평가
- 시스템에서 제어하는 구성 요소에 대한 평가
- 프롬프트 및 컨텍스트에 따른 결과를 나타냄
- Extracting structured information: LLM이 정보를 얼마나 잘 추출하는지
- QA: 사용자의 질문에 얼마나 잘 답변하는지
- RAG: 검색된 문서와의 관련성
- ex) Diversity, User feedback, GT-based Metrics, Answer Relevance, QA Correction, Hallucinations, Toxicity, …
로 나뉜다.
Coding Tasks
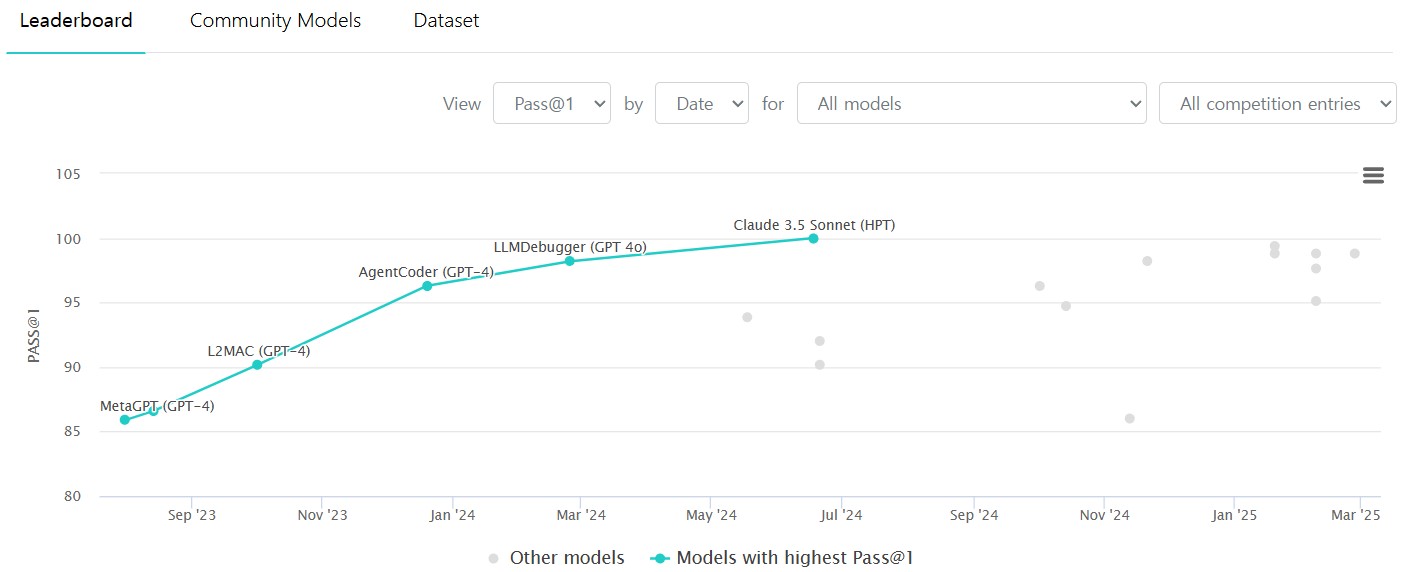
Coding에 대한 평가 방법은 HamanEval, MBPP(Mostly Basic Python Programming)로 나눌 수 있다.
- HamanEval: LLM의 성능을 측정하기 위해, 프로그래밍 과제 및 문제를 데이터셋으로 가지고 있는 평가 도구
- 실질적인 문제들로 평가하며, LLM에서 생성된 python 코드가 문제를 얼마나 pass하는지를 측정함
- MBPP: python 프로그램을 합성하는 능력을 측정
- 974개의 프로그램이 포함된 데이터셋
- 프로그래밍 표준 문법 및 라이브러리를 다루는 능력 및 품질을 평가

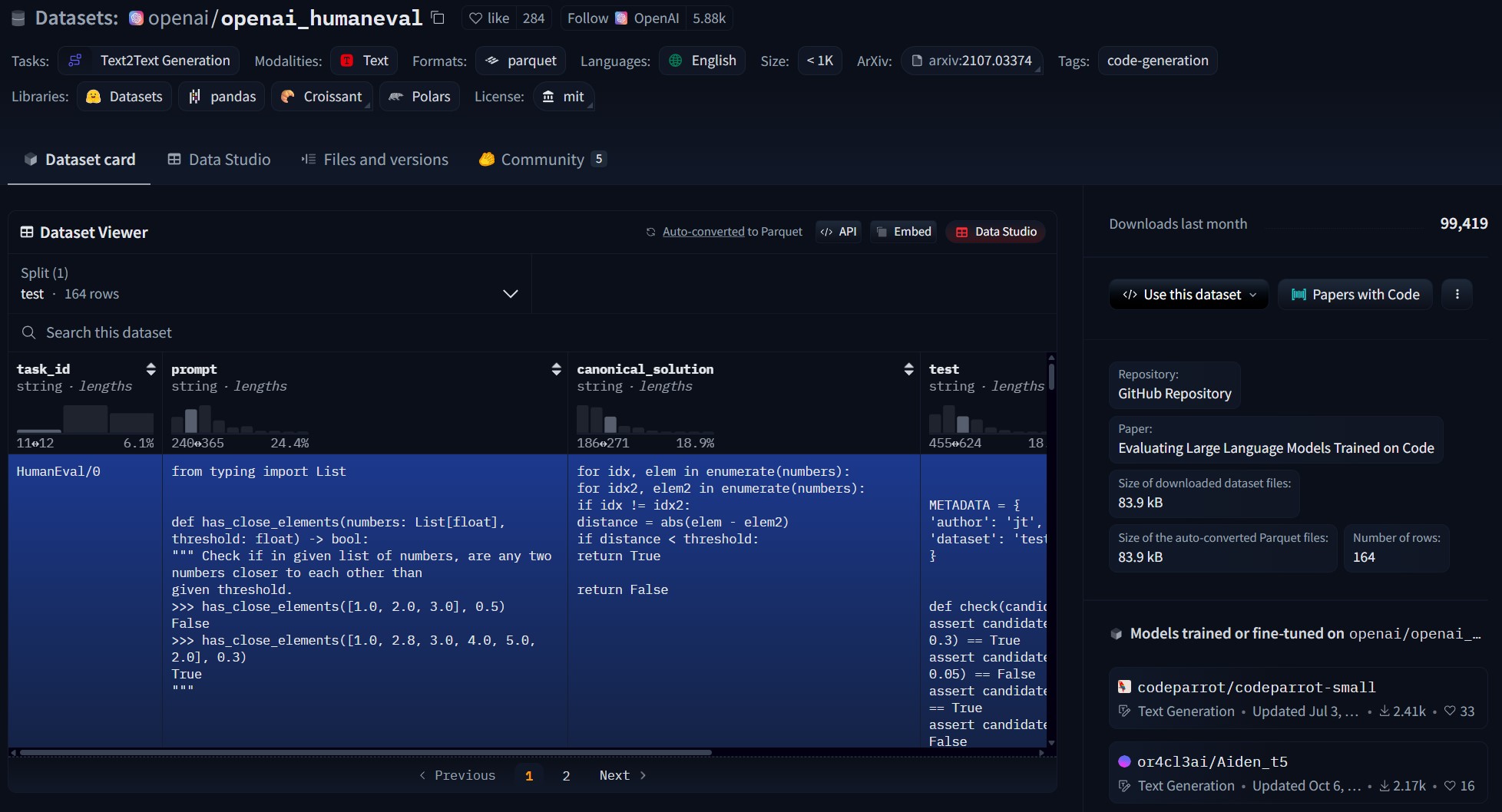
HumanEval
아래와 같이, 문제에 대한 prompt와 정답 코드, output check를 위한 assert를 포함하고 있다.
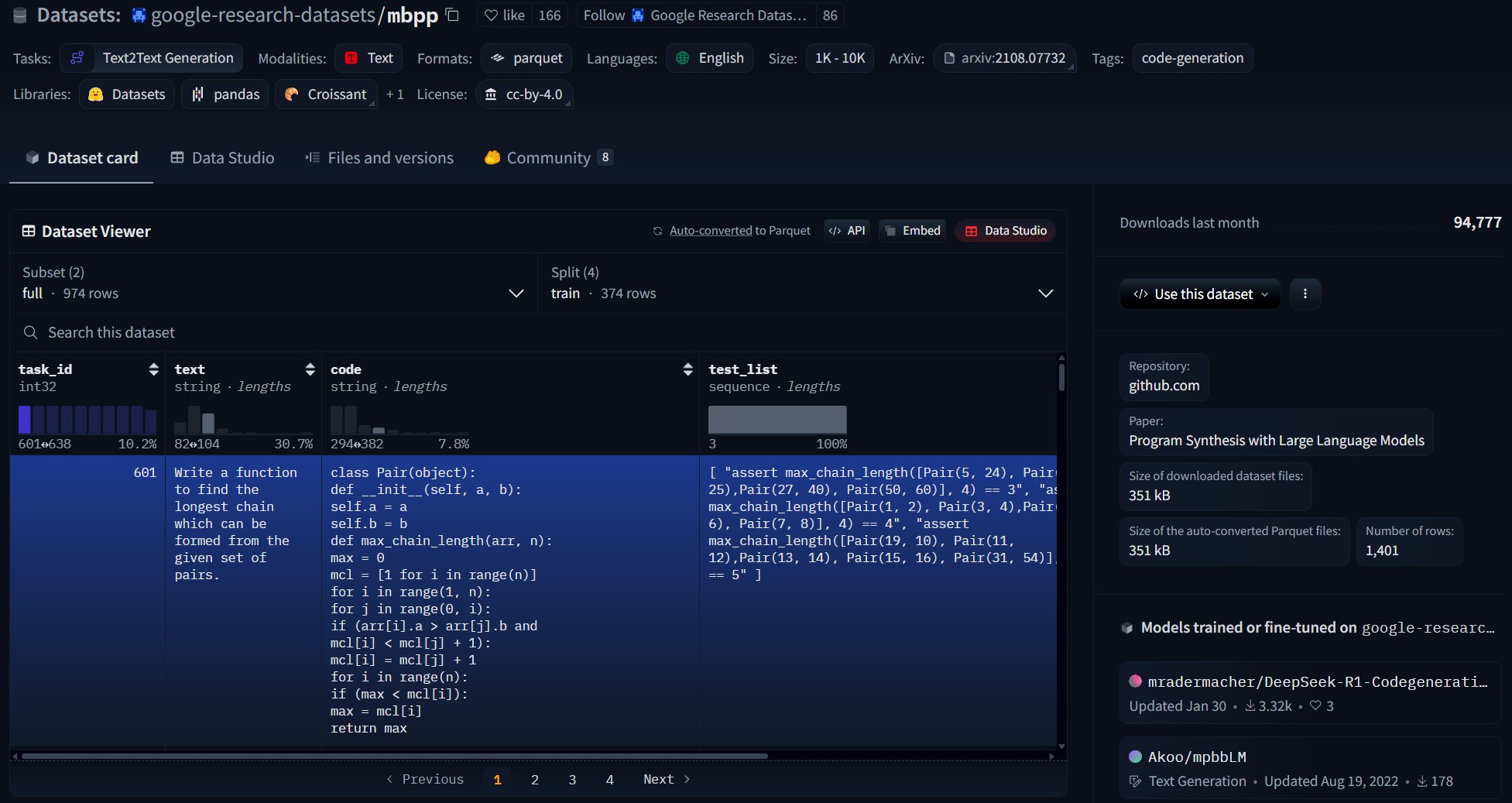
MBPP
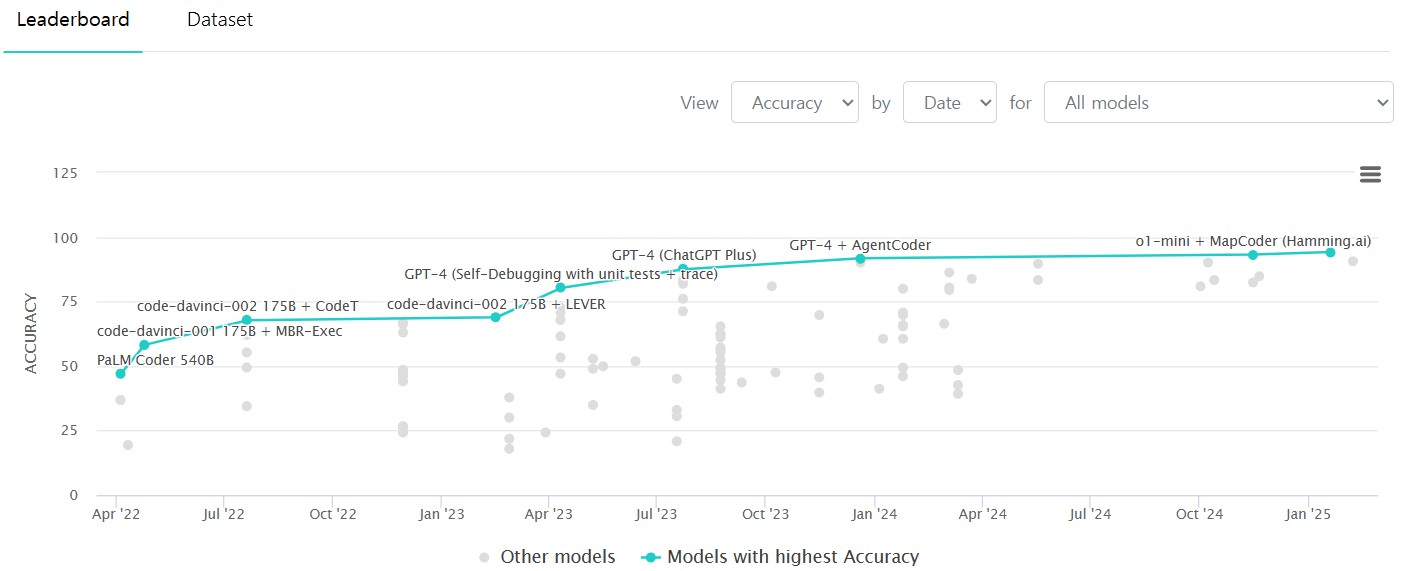
MBPP는 python에 특화된 metric으로, 코드 n 번 생성에 대한 실행 횟수, 코드의 품질 및 정확성을 테스트할 수 있다.
Chatbot Assistance
Chatbot Assistance에 대한 평가 방법도 2가지로 나눌 수 있다.
- Chatbot Arena: 익명의 모델 n개를 사람이 직접 사용해보고 투표를 진행하는 방식
- MT Bench: 대화나 지침 준수에 대한 능력을 평가함
- n번 질문을 했을 때, 어떤 성능 및 특성을 가지는지 확인을 하는 특성
- Writing, Extraction, Reasoning, Math, Coding 등 사람이 많이 사용하는 8개의 category들에 대해 대답을 잘하는지에 대한 평가를 수행
Chatbot Arena
LMSYS에서 운영하고 있음. A와 B 모델에 대해 두 LLM 모델이 답변을 하고, 답변에 대해 투표
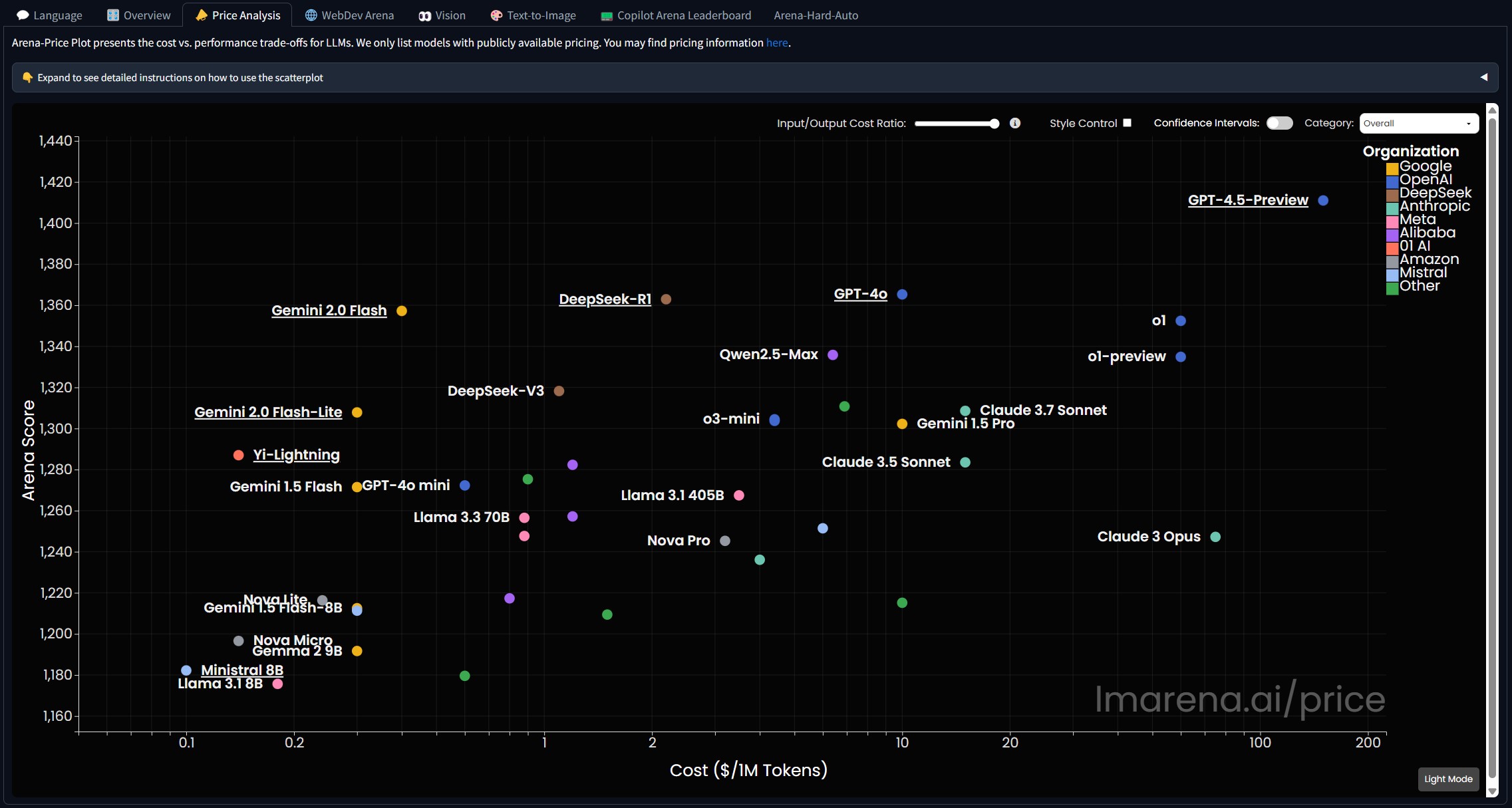
아래와 같이, LLM에 대한 순위 및 여러 task에 대한 성능도 시각적으로 표기해준다.
MT Bench
모델의 이해력 및 추리 능력, 대화형 응답에 대한 능력을 종합적으로 평가
질문의 category, 질문, 답변에 대한 refernce로 데이터셋이 구성되며, 여러 범주에 대한 성능을 객관적으로 평가할 수 있다.
n번 질문들 통해, 공통적인 답변을 하는지 판단하고, GPT-4를 통해 답변의 정확성을 판단함
Reasoning
주어진 정보를 바탕으로 논리적인 답변을 만들어내는 것을 추론이라고 함
- ARC Benchmark: 과학적 지식 및 문제 추론에 대한 평가
- HellaSwag: 일반적인 상식 추론을 평가하는데 사용
- MMLU: 언어 자체에 대한 이해
- TriviaQA: 퀴즈에 대한 정답을 평가
- WinoGrande: 문제가 주어졌을 때, 논리적으로 추론을 잘하는가? 문맥에 대한 이해 능력
- GSM8k: 수학 문제에 대한 추론 능력 평가