Switch Transformer
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Table of contents
Summary
일반적으로, ML model은 입력에 대해 동일한 parameter를 사용하여 추론을 수행한다. 하지만 대규모 데이터셋에 대해 더 유연하고 효율적인 계산을 위해 MoE(Mixture of Experts)가 쓰인다. MoE는 입력에 대해 layer의 하위 parameter를 sparsely-activated하여 연산을 수행한다. 많은 parameter 수에 비해 일정한 활성화 parameter를 가져, 효율적인 추론을 수행한다. 하지만, 어떤 parameter를 활성화시킬지에 대한 router 설계가 복잡하다. Switch Transformer는 이런 routing algorithm을 단순화하여 직관적이고 효율적인 모델을 설계한다.
Switch Transformer의 contribution은
- MoE의 단순화
- 제한된 resource에서 성능 향상 및 T5 모델의 학습 속도를 7배 향상
- 작은 모델로 좋은 성능의 distillation
- Finetuning technique 향상
- bloat16으로 학습
- 더 많은 export를 위한 initialize scheme
- Finetune 및 multi-task 학습을 위한 expert regularization
- bloat16으로 학습
- parallelism을 통한 data, model, export의 효율적인 결합
결과적으로, switch transformer는 scalable하고 effective한 MoE Transformer 모델로, 기존 모델보다 직관적이고 stable하며 같은 size의 dense model에 비해 efficient하다.
Switch Transformer
Switch Transformer는 parameter를 늘리면서, 효율적인 계산을 수행하는 것을 목표로 한다. 수행 연산량과 무관하게 parameter의 수가 model scaling의 중요한 축이라고 생각하며 sparsely activated model을 설계한다.

Figure 1. Illustration of a Switch Transformer encoder block.
Simplifying Sparse Routing
기존 TopK Routing MoE는 입력에 대해 \(W_g\)를 곱하고 Noisy Top-K를 적용하여 Softmax를 통해 gating probability를 얻는다. 학습 과정에서 \(W_g\)는 activated export의 결정을 학습하고, Top-k는 효율성은 유지하면서도 전체 모델 용량은 크게 확장하도록 한다. 학습 초기에 export imbalance를 해결하기 위해 noise를 추가하여 exploration을 유도한다. 논문의 저자는 각 token이 2개 이상의 export를 선택하여 학습하여야 효과적이라는 직관을 제시하고, 후속 연구에서 export의 수에 따라 높은 k가 중요하다는 것을 보인다.
Switch Transformer에서는 이와 반대로, 1개의 export만 활성화하여 router를 단순화하며 성능을 유지한다. (Switching Layer)
Switching Layer는 아래와 같은 이점이 있다.
- router computation 감소
- expert batch size 감소
- communication cost 감소
Efficient Sparse Routing
Distributed Switch Implementation
일반적으로 tensor의 shape나 연산은 compile 시, 결정되지만 switch transformer는 router 때문에 동적이다. 따라서 균등한 연산 할당과 마진을 위해 아래와 같이, export capacity를 설정한다.
\[\begin{gather} \text{expert capacity} = \frac{\text{tokens per batch}}{\text{number of experts}} \times \text{capacity factor} \end{gather}\]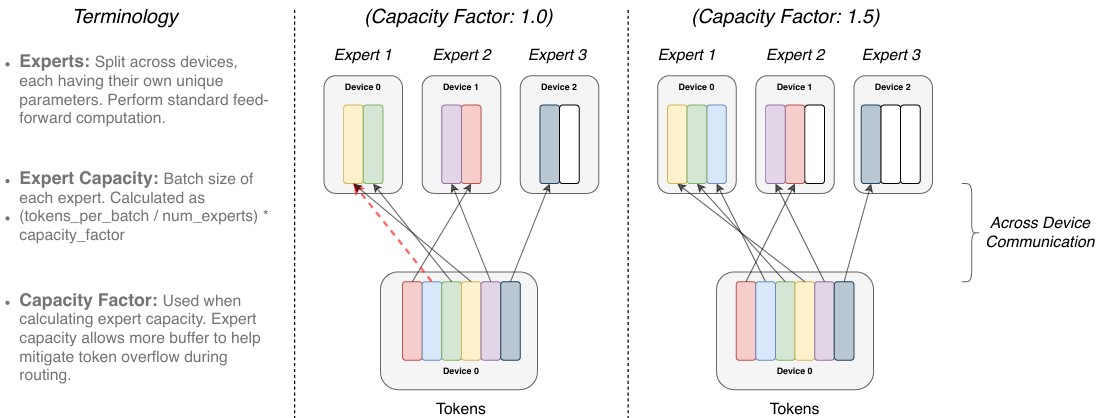
Figure 2. Illustration of token routing dynamics. Expert Capacity는 각 export 당 처리할 수 있는 batch size (token 수)를 의미하며, Capacity Factor는 Capacity를 계산할 때 사용되고 어느정도 overflow를 허용하기 위한 buffer와 같으며, 보통 1.0 ~ 1.25가 사용된다. Capacity를 넘은 token들의 경우, drop 되며 다음 layer에 residual 방식으로 전달된다.
너무 큰 expert capacity는 높은 계산량과 메모리를 사용하게 된다. 따라서, dropped token을 낮추며 expert capacity도 낮추기 위해 switch transformer는 auxiliary load balancing loss를 사용한다.
A Differentiable Load Balancing Loss
각 switch layer에서 export에 대한 load-balancing을 위해 auxiliary loss를 사용하고, 전체 loss에 더하여 학습을 진행한다.
\(N\)개의 expert와 batch \(B\), token \(T\)에 대해, \(f_i, P_i\)는 각각 expert \(i\)에 할당된 token과 router probability의 비율일 때,
Putting It All Together: The Switch Transformer
Switch Transformer에서 설계한 model의 구조는 및 다른 MoE Transformer와의 비교는 아래와 같다.
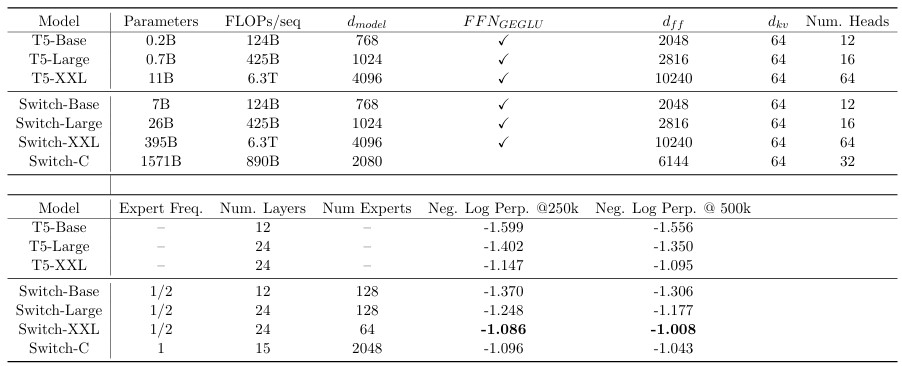
Table 1. Switchmodel design and pre-training performance.
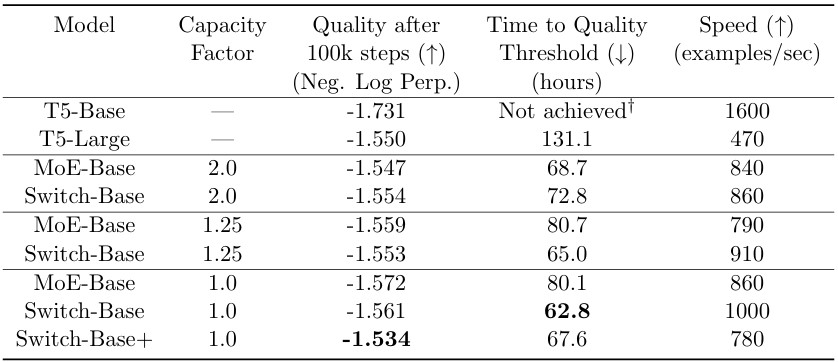
Table 2. Benchmarking Switch Transformer & MoE Transformer. Switch Transformer는 다른 MoE보다 speed-quality가 좋고, Memory 사용량이 작다. 또한 낮은 capacity factors에서도 좋은 성능을 보인다.
Improved Training and Fine-Tuning Techniques
Sparse expert model은 일반적인 모델에 비해, layer에서 routing이 이뤄지기 때문에 안정적으로 학습이 되지 않을 수 있다.
Selective precision with large sparse models
이런 불안정성은 bloat16으로의 학습을 어렵게 하기 때문에, 선택적으로 float32로 casting하여 학습한다.
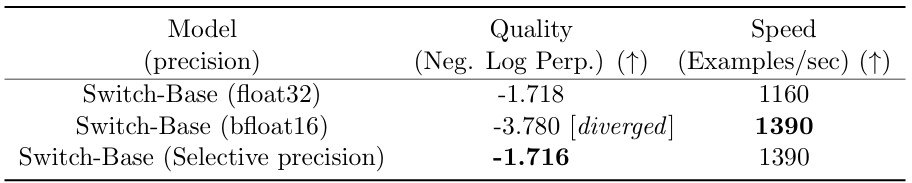
Table 3. 일부 parameter만 float32로 casting하여 학습하는 것이 학습 안정성과 inference time에 도움을 준다.
Regularizing large sparse models
일반적으로 NLL에서는 large data corpus를 통해 pre-training을 진행한 후, 소규모 data corpus로 finetune을 수행한다. 하지만, 이런 방법은 overfitting의 문제가 발생할 수 있다.
Switch Layer에서는 dense model에 비해 많은 parameter를 가지고 있기 때문에 overfitting이 더 크게 나타날 수 있다. 따라서, export dropout을 통해 overfitting을 완화한다.
- 각 expert 레이어의 중간 feed-forward 연산 부분에서만 dropout 비율을 크게 증가시키는 방식
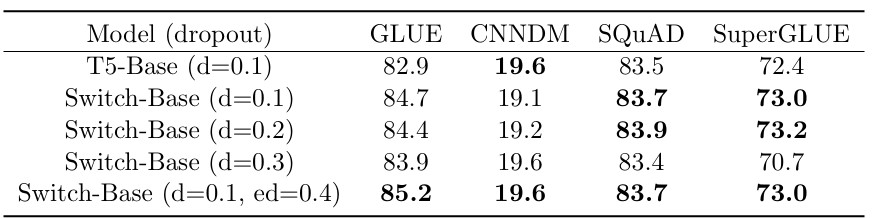
Table 4. Switch Transformer에 Dropout을 적용한 것에 대한 성능. Export Layer에만 더 큰 dropout을 적용하는 것이 성능 향상에 도움을 준다.
Scaling Properties
Export를 늘리는 것은 단순히 router에만 연산량 증가를 가하기 때문에 효율적이다. 따라서, 저자들은 export 수에 따른 Scaling을 조사했다.
Scaling Results on a Step-Basis
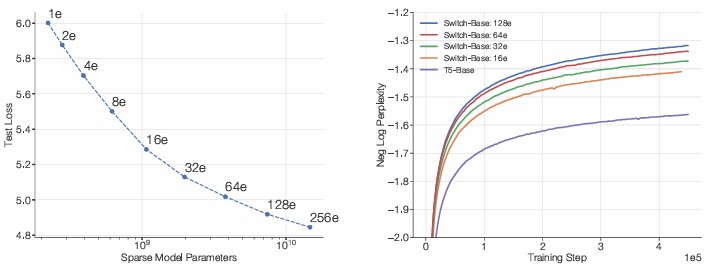
Figure 3. Left: Export 수 증가에 따른 성능 향상. Right: 학습 step당 negative log perplexity
위 그림과 같이, export 수가 증가할 때, scaling benefit이 있으며 학습 속도 및 효율성이 좋아진다. 하지만, 많은 export 수는 학습 불안정성과 어려움이 존재하기 때문에 신중한 선택이 필요하다.
Scaling Results on a Time-Basis
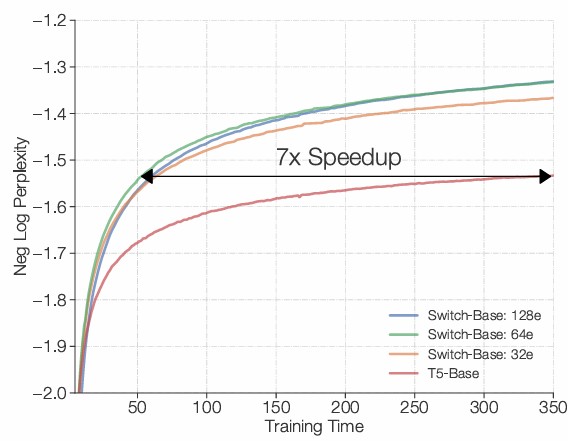
Figure 4. Switch Transformer는 dense Transformer에 비해 명확한 이점을 보인다.
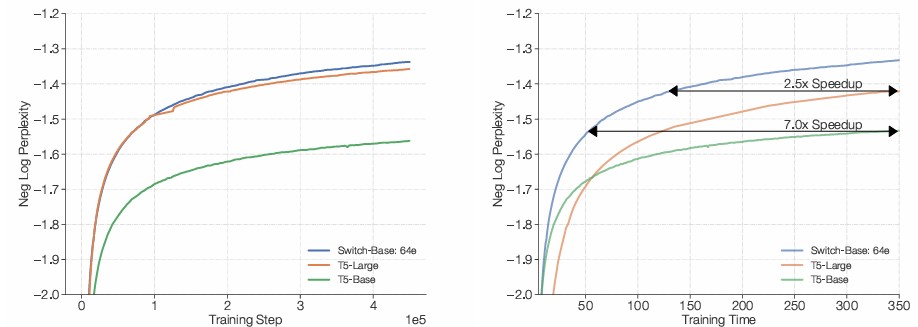
Figure 5. Left: Switch-Base는 높은 샘플 효율성(sample efficiency)을 보인다. Right: Switch-Base는 T5-Large 대비 2.5배의 속도 향상을 보인다.