Delving Deep into the Generalization of Vision Transformers under Distribution Shifts
Delving Deep into the Generalization of Vision Transformers under Distribution Shifts
Table of contents
- Introduction
- Distribution Shifts and Evaluation Protocols
- Generalization-Enhanced ViT
- Systematic Study on ViTs Generalization
- Studies on Generalization-Enhanced ViTs
ViT의 generalization, Shift 등 특성에 관한 연구
Introduction
ViT는 benchmark에서 뛰어난 성능을 이루고 많은 연구가 진행되었지만, generalization 성능에 관한 연구는 많이 이뤄지지 않음
일반적으로, train과 test의 data가 같은 distribution에 위치한다고 가정하지만, 실제로는 그렇지 않은 경우가 많기 때문에 Out-of-Districution과 같은 generalization performance는 중요함
따라서, 저자는 distribution shifts (DS)에 대한 ViT의 성능을 조사
DS는 semantic information에 관한 foreground object(pixel-level elements, object textures, and shapes, object parts, object)와 background information로 구성됨
DS는 일반적으로 semantic에서 변화를 야기하기 때문에 저자는 4개의 concept으로 DS를 분류
- Background shifts
- Corruption shifts
- Texture shifts
- Style shifts
ML에서 한 task에 optimize되어 있으면, 다른 task에 대해선 성능이 좋기가 힘듦 (no-free-lunch theorem)
따라서, 인간과 비슷하게 generalization이 되려면, 어느 정도 사람의 인지와 비슷한 inductive bias를 가져야 한다고 볼 수 있음
ViT는
- Background, texture에 약한 bias를 가지고, shape, style에 큰 bias를 가짐
\(\rightarrow\) 인간과 비슷 - Model이 커짐에 따라, bias가 증가
\(\rightarrow\) Corruption, background shift가 증가하고, IID 및 OOD의 격차가 줄어듦
\(\rightarrow\) Local에 관한 일반화 성능이 좋아짐 - 큰 patch로 훈련하는 것은 texture shift에만 좋고 나머지 성능에는 \(\downarrow\)
따라서, 저자는 generalization이 좋은 GE-ViT를 제시
Distribution Shifts and Evaluation Protocols
Taxonomy of Distribution Shifts
Background shifts
Background의 경우, label estimation에서 auxiliary cue로 간주되지만, 이런 배경이 estimation에서 지배적으로 작용할 수 있다는 연구 결과가 존재함
따라서, Model의 배경, 전경에 대한 의존도 benchmark인 ImageNet-9를 통해 분석을 수행
Corruption shifts
이미지에 포함된 자연적인 noise로, 이미지 촬영, 처리 단계에서 발생함
일반적으로 pixel-level element에 영향을 미치고, ImageNet-C를 통해 분석을 수행
Texture shifts
Color와 intensity는 spatial information을 제공하고, classify에 중요함
Stylized-ImageNet을 통해 분석을 수행
Style shifts
Style은 texture, shape, object part 등 복합적인 요소로 인해 결정됨
ImageNet-R, DomainNet을 통해 분석을 수행
Evaluation Protocols
일반적인 classification task의 model과 비슷하게, encoder \(F\) (feature extraction), classifier \(C\)로 설정
Train, validation, OOD dataset을 각각 \(\mathcal{D}_{train}, \mathcal{D}_{iid}, \mathcal{D}_{ood}\), 각 dataset의 data 수를 \(\mathcal{N}_{train}, \mathcal{N}_{iid}, \mathcal{N}_{ood}\)로 설정
Accuracy on OOD Data.
IID/OOD Generalization Gap.
IID에 비한 OOD 성능
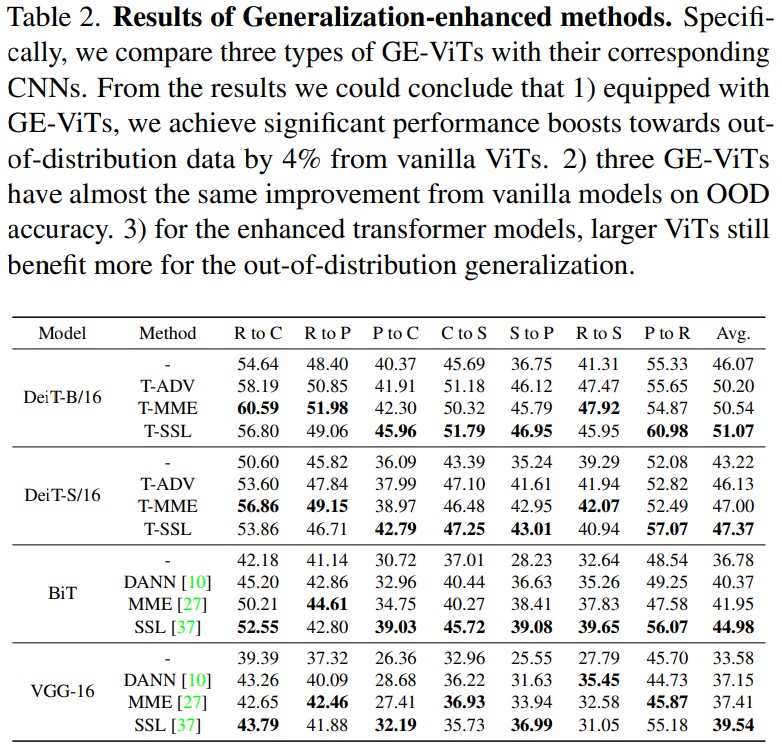
Generalization-Enhanced ViT
OOD를 개선하기 위해 GE-ViT를 설계
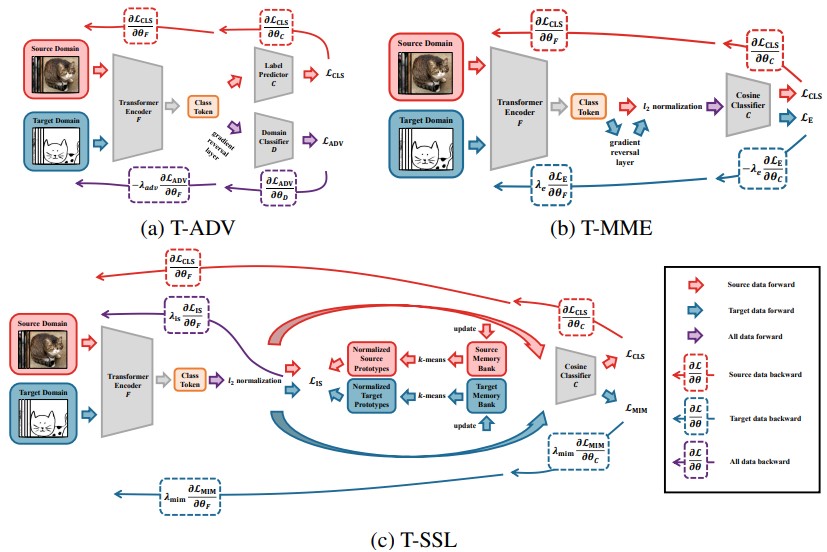
T-ADV: Adversarial Training
\[\begin{align} L_{CLS} &= \sum_{(x,y)\in\mathcal{D}_s} \mathcal{H}(\sigma(C(F(x))),y), \\ L_{ADV} &= \sum_{(x,y_d)\in\mathcal{D}_s,\mathcal{D}_t} \mathcal{H}(\sigma(D(F(x))),y_d), \\ &= (\hat{\theta}_F, \hat{\theta}_C) = \argmin_{\theta_F,\theta_C}L_{CLS}-\lambda_{adv}L_{ADV}, \\ &= \hat{\theta}_D = \argmax_{\theta_D}L_{ADV}, \end{align}\]
Domain-invariant representation을 학습하기 위해, adversarial training를 이용하여 \(F\)와 domain classifier \(D\) 훈련GRL(Gradient Reversal Layer)이 F와 D 사이에 있기 때문에, F에선 \(L_{ADV}\)를 maximize하는 것과 같이 훈련됨
T-MME: Information Theory
\[\begin{align} L_{CLS} &= \sum_{(x,y)\in\mathcal{D}_s} \mathcal{H}(\sigma(C(F(x))),y), \\ L_{E} &= \sum_{x\mathcal{D}_t} \mathcal{H}(\sigma(C(F(x)))), \\ &= \hat{\theta}_F = \argmin_{\theta_F}L_{CLS}+\lambda_{e}L_{E}, \\ &= \hat{\theta}_C = \argmin_{\theta_C}L_{CLS}-\lambda_{e}L_{E},, \end{align}\]
Target data의 conditional Entropy에 대한 minmax process를 이용하여, Cosine Classifier C를 학습하며 distribution gap을 줄임
Unlabeled에 대해 C의 entropy는 maximize하고 F는 minimize하여, 대상 분포에 더 잘 clustering하도록 함T-SSL: Self-Supervised Learning
Systematic Study on ViTs Generalization
Background Shifts Generalization Analysis
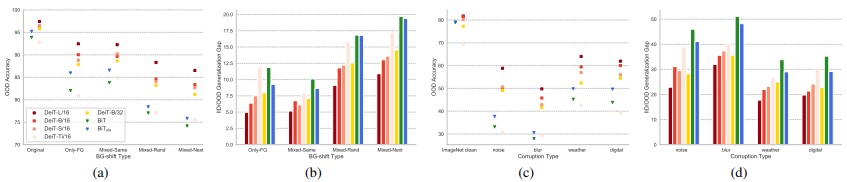
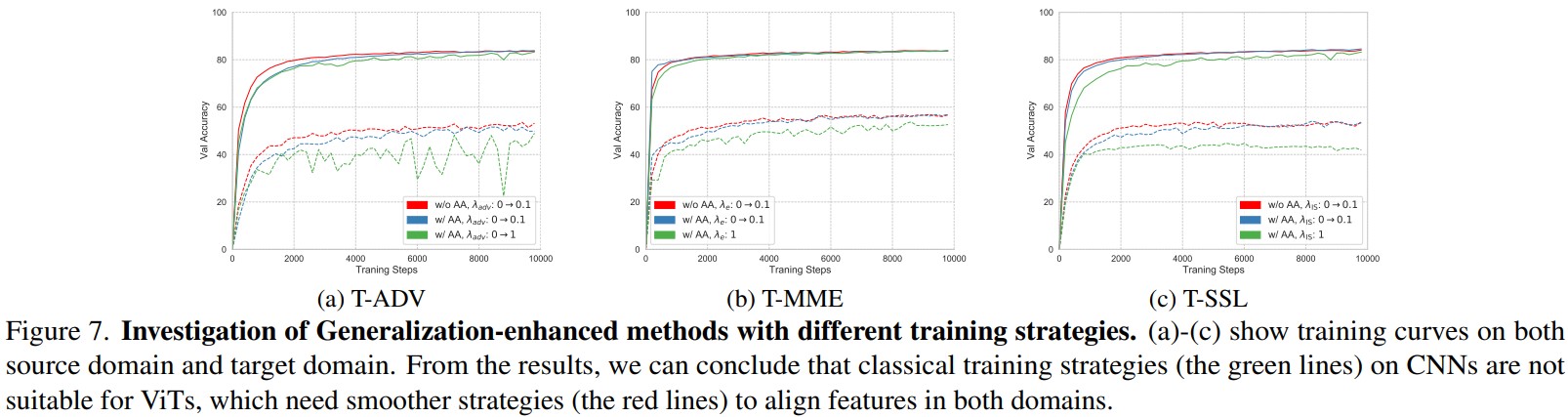
ViTs perform with a weaker background-bias than CNNs. Class와 관련있는 배경에 대한 Mixed-Same과 랜덤한 배경인 Mixed-Rand의 정확도를 비교한 결과, VIT는 CNN보다 Background bias가 적음 (Fig. 2a)
또한, 훈련 중 data augmentation을 다양하게 적용하는 것이 background-shifted data에 대한 성능이 좋음
A larger ViT extracts a more background-irrelevant representation. ViT가 클수록 모델이 foreground에 더 집중하는 경향이 있음
큰 ViT 모델이 OOD에 성능이 더 좋고, background-irrelevant representation을 더 학습하려고 함
Corruption Shifts Generalization Analysis
- ViT가 scale이 커짐에 따라 일반화 성능이 좋아지고, 대부분 CNN 보다 corruption shifts가 좋음
- Patch size가 크면 일반화 성능이 좋아짐
Texture Shifts Generalization Analysis
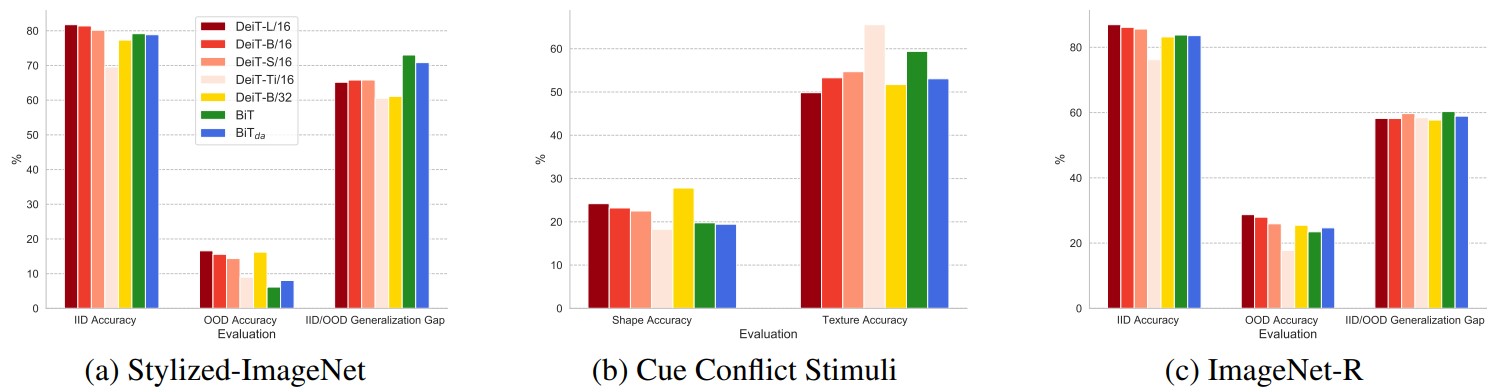
\(\rightarrow\) Results on Stylized-ImageNet, Cue Conflict Stimuli and ImageNet-R.
- ViT는 shape에 대한 강한 bias를 가지고 있고, 이는 mdoel scale과 positive correlation
- 따라서, texture에 일반화가 잘 되며 국부적인 corruption에 영향을 덜 받음
- 큰 patch size 일수록 global feature에 잘 집중함
Style Shifts Generalization Analysis

\(\rightarrow\) Results on DomainNet.
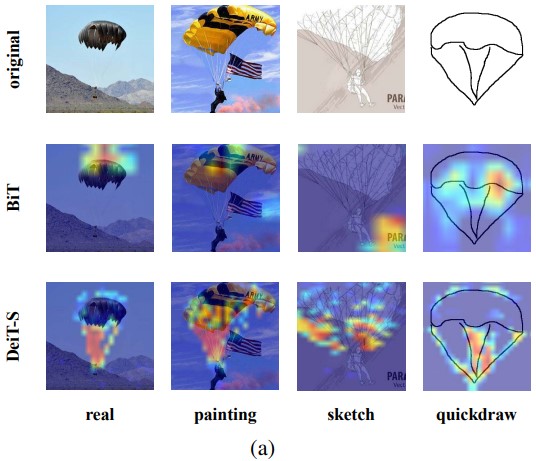 | 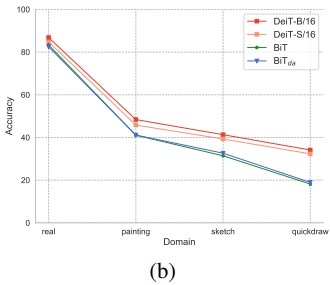 |
- 대부분 ViT의 OOD가 CNN의 OOD를 능가함
- 예술 작품 task에 대해선 ViT가 큰 효과는 없었음
- 예술 작품 task에 대해선 ViT가 큰 효과는 없었음
또한, ViT의 경우 pretrained를 더 잘 활용하고 downstream 성능이 좋음
- Structure만 남은 degraded image에서 ViT는 structure만 있어도 이미지의 feature를 잘 capture 했으며 structure에 큰 bias를 가짐
- ViT는 각각 layer level에서 DS level을 제거함
Studies on Generalization-Enhanced ViTs