StyelGAN-NADA
StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators
Table of contents
TODO: Update detailed study log of this paper…
Summary
기존에는 domain adaptation을 하기 위하여 해당 dataset이 필요했음
이를, 대규모 dataset으로 학습되어 있는 CLIP을 이용하여 adaptation을 수행함
\(\rightarrow\) 비슷하게 style로는 CLIPstyler가 있음
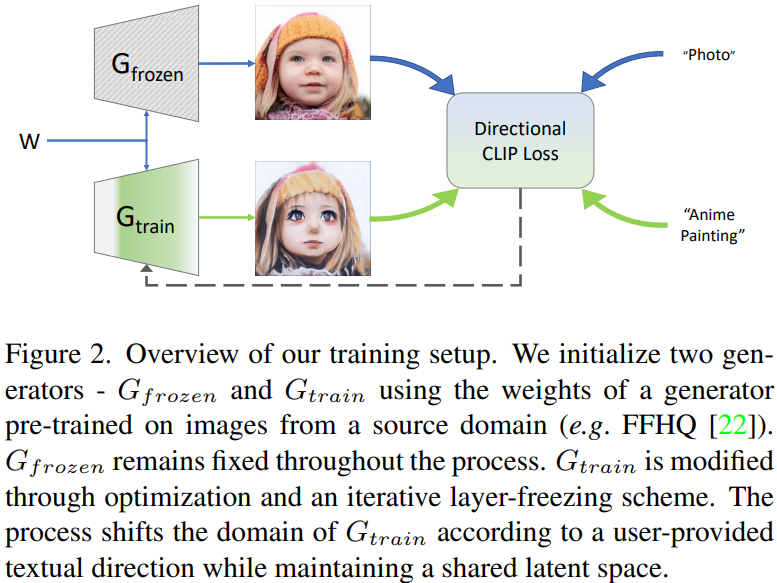 |  |
- frozen으로부터 나온 이미지, adaptation에 관한 이미지, 각각의 text 들을 CLIP에 넣어, directional CLIP Loss 사용
- Image 간의 차이, texture 간의 차이에 대해서 cosine distance를 사용하여 align
- MSE의 경우 vector의 방향이 비슷해도 크기에 영향을 많이 받고,
- Cosine은 거리보단 방향에 영향을 많이 받음
- 따라서 cosine이 vector를 align하기에 더 좋음
- 기존의 global CLIP Loss(style image와 target texture와의 Loss만 가깝게 함)는 문제가 있었음 \(\rightarrow\) 컨텐츠가 망가질 수 있음
\(\rightarrow\) 훈련이 불안정함
| $$ \begin{gather} ∆T = E_T (t_{target}) − E_T (t_{source}), \\ ∆I = E_I (G_{train} (w)) − E_I (G_{frozen} (w)), \\ L_{direction} = 1 − \frac{∆I · ∆T}{|∆I| |∆T|}. \end{gather} $$ | 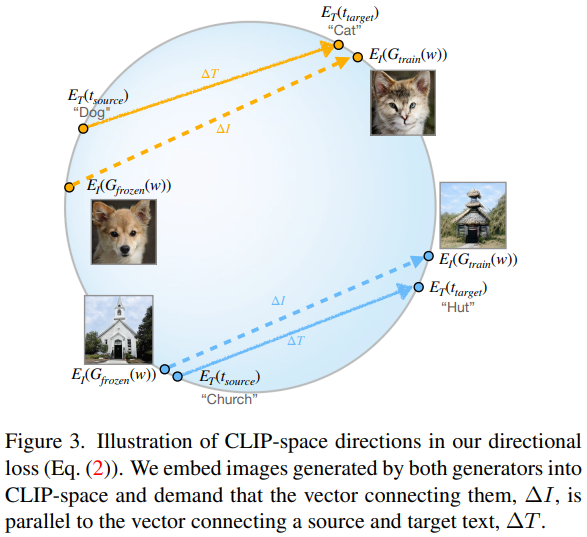 |
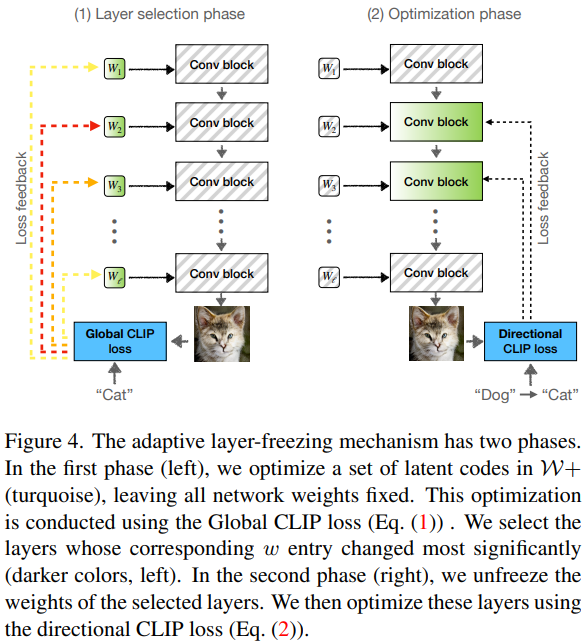
훈련의 경우, w space를 이용하여, 가장 변화가 큰 부분을 선택한 후, 해당 layer에 해당하는 conv layer만 업데이트
\(\rightarrow\) toRGB가 있기 때문에 중간 layer를 requires_grad=False로 설정해도 훈련이 진행되는 듯
- 일반적으로 texture만 바꾸는 것은 빠르게 수렴하고 모드 붕괴 또는 과적합 됨
- 하지만, 효과적인 style update를 위해선 오랜 훈련이 필요함
- 이전 연구에서 하위 모델 집합만 업데이트하면 품질이 향상된다는 결과가 있었음
- 따라서, 업데이트하는 layer의 수를 제한하여 모델 복잡성과 과적합 가능성을 줄임